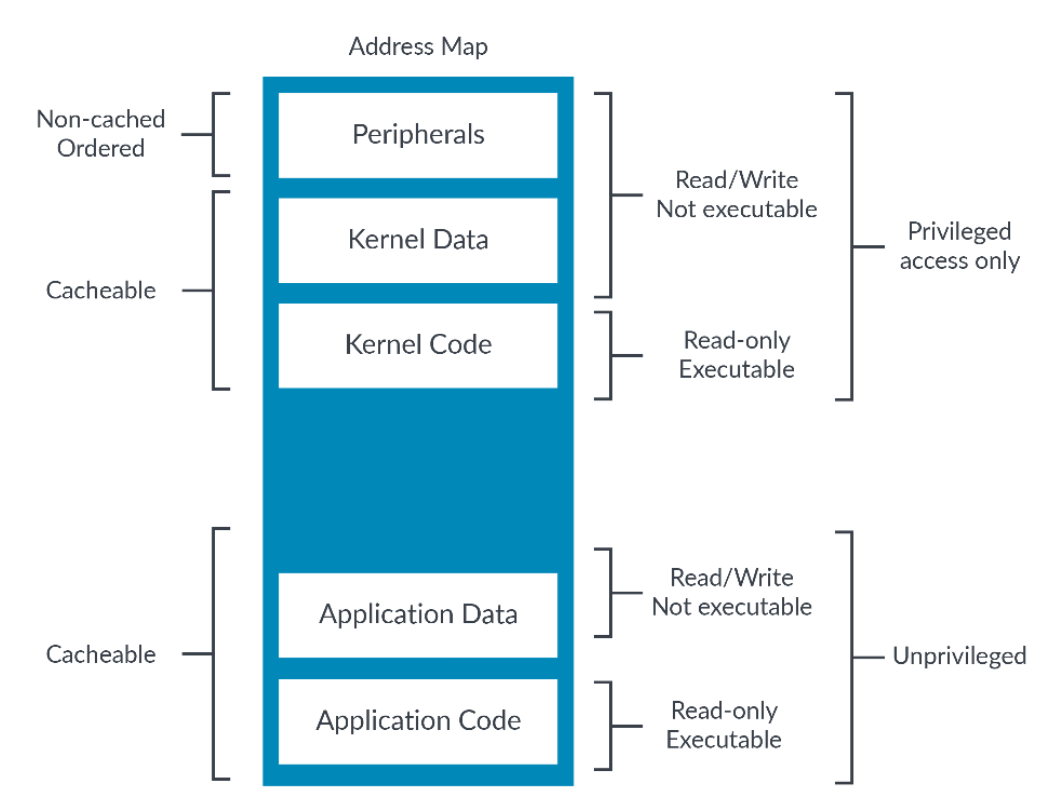
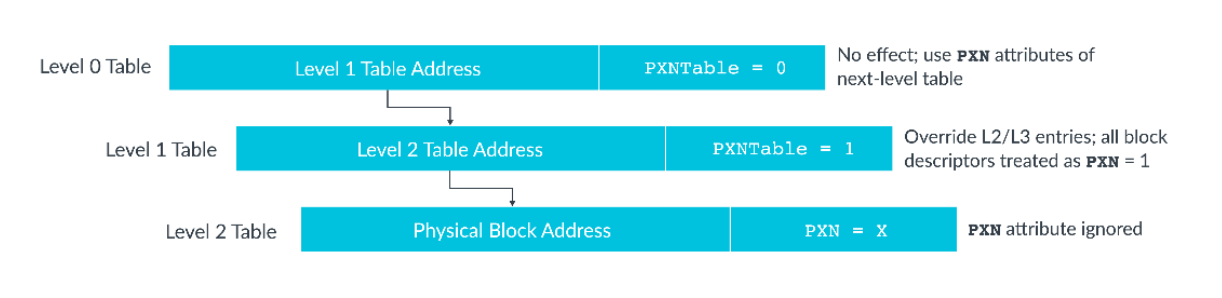
ARMv8.1-A引入了脏状态,记录了页表项对应的内存区域是否被写入过。当启用脏状态特性时,创建的新页表项会被设置为只读,且DBM(Dirty
Bit
Modifier)置位。DBM会改变访问控制位(AP[2]和S2AP[1])的功能,使其变为记录脏状态。当向新创建的页表项对应的内存区域写入时,硬件会自动将其访问权限设置为读写。综上,DBM置位时,只读的页表项是没有被写入过的,读写的页表项是被写入过的。
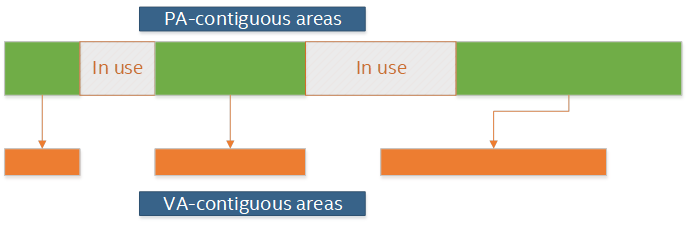
DPDK不区分PA和IOVA,而是统一称作IOVA。但是,DPDK会区分PA直接作为IOVA(IOVA
as PA),还是IOVA匹配用户空间虚拟地址(IOVA as VA)这两种情况。
IOVA as
PA模式下,分配给DPDK的所有内存区域的IOVA都是实际的PA,并且虚拟内存的布局与物理内存的布局相同。IOVA
as
PA的优势在于适用于所有硬件,并且与内核空间之间也很适配(因为物理地址到内核空间虚拟地址的映射是直接映射)。IOVA
as
PA的缺点之一在于需要root权限,否则无法获取内存区域的真实物理地址。缺点之二是物理内存的布局会影响虚拟内存的布局。如果物理内存碎片化比较严重,那么虚拟内存也会是相同程度的碎片化,从而影响DPDK应用对虚拟内存的使用。
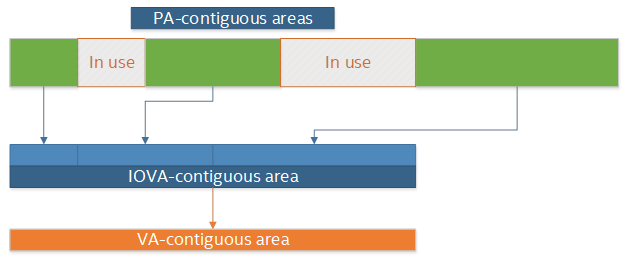
IOVA as
VA模式下,物理内存会被重新排列,以匹配虚拟内存空间的布局。DPDK通过内核提供的功能完成这一操作,而内核则是通过IOMMU来完成物理内存重映射的。IOVA
as
VA的优点之一就是无需root权限,之二就是避免物理内存的碎片化影响到虚拟内存。IOVA
as VA的缺点在于需要IOMMU的支持。
VFIO(Virtual Function
I/O)是内核基础设置,可以把设备寄存器和中断暴露给用户空间应用,并且可以利用IOMMU建立IOVA映射。
// 重试循环,执行成功就退出循环,失败则继续循环 do { /* Reset n to the initial burst count */ // 重设n和old_head。n是想要入队的数据数量,old_head是当前的ring->prod_head n = max;
*old_head = r->prod.head;
/* add rmb barrier to avoid load/load reorder in weak * memory model. It is noop on x86 */ // 在ARM架构中,这实际上是一条dmb ishld指令,能够保证这条指令之前的所有读指令都完成后, // 才能执行这条指令之后的内存访问(包括读写)指令。 ish指的是inner shareable domain, // 可理解为整个机器范围,也就是所有核心上执行的指令中,这条指令之前的读指令执行完成后, // 才能执行这条指令之后的内存访问指令。所以这条指令在防谁呢? rte_smp_rmb();
/* * The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * *old_head > cons_tail). So 'free_entries' is always between 0 * and capacity (which is < size). */ // prod.head,prod.tail,cons.head,cons.tail四个索引的范围并不是[0,r->size), // 而是[0,2^32),每当需要使用这些索引时,将进行index&(size-1),来得到合法的索引。 // 当然,这样以来size必须是2的幂了,但优点在于不必再判断各种边界条件。capacity是ring // 中真正可用的entry数量,等于size-1。留一个位置不用的原因应该是为了方便区分空ring和满ring, // 否则这两种情况都是prod==cons,不好分辨。所以在创建时设置容量为1024,实际上会得到容量为 // 1023的ring。当然,可以在创建ring时强制不使用2的幂作为容量,如此以来size会被设置为 // 大于该容量的最近的2的幂(最坏情况下要浪费一半的空间),capacity会被设置为指定的容量。 // 另外,这capacity个可用位置并不是固定在ring的某个位置,比如固定前capacity个位置可用, // 其他位置留作他用。capacity仅仅是一个数字限制,入队元素时用作检查,数据还是在ring的 // 整个size内入队出队的。 // // 四个索引逻辑上只会前进(增加)而不会后退(减少),实际上只会在到达2^32范围时重新回到0。 // 下列式子无论是在正常情况下,还是cons.tail位于接近2^32的位置而prod.head已经回到0附近 // 的情况下,都能利用32位无符号数的溢出计算出正确的结果。 *free_entries = (capacity + r->cons.tail - *old_head);
/* check that we have enough room in ring */ // unlikely()和likely()可以告诉编译器这个判断更可能为false或true,从而可以对分支预测 // 进行优化。这里根据入队策略设置了n的值,如果是必须入队固定数量的策略,那么空闲entry不足时 // 不进行入队,直接返回;如果是尽可能入队的策略,那么根据空闲entry数量调整n的值。 if (unlikely(n > *free_entries)) n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *free_entries;
static __rte_always_inline void __rte_ring_update_tail(struct rte_ring_headtail *ht, uint32_t old_val, uint32_t new_val, uint32_t single, uint32_t enqueue) { // 如果是要入队的话,那么加一个写屏障,dmb ishst,也就是等待写操作都完成之后, // 再更新prod.tail,防止prod.tail先被写入了,导致消费者直接开始消费空位置。 if (enqueue) rte_smp_wmb(); else rte_smp_rmb(); /* * If there are other enqueues/dequeues in progress that preceded us, * we need to wait for them to complete */ if (!single) // 阻塞,直到r->prod_tail等于prod_head rte_wait_until_equal_32(&ht->tail, old_val, __ATOMIC_RELAXED);
static __rte_always_inline unsignedint __rte_ring_move_cons_head(struct rte_ring *r, unsignedint is_sc, unsignedint n, enum rte_ring_queue_behavior behavior, uint32_t *old_head, uint32_t *new_head, uint32_t *entries) { unsignedint max = n; int success;
/* move cons.head atomically */ do { /* Restore n as it may change every loop */ n = max;
*old_head = r->cons.head;
/* add rmb barrier to avoid load/load reorder in weak * memory model. It is noop on x86 */ // 注意这里保证的是先读cons.head,后读prod.tail,与入队时正好相反,但是这是在保护什么? rte_smp_rmb();
/* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * cons_head > prod_tail). So 'entries' is always between 0 * and size(ring)-1. */ *entries = (r->prod.tail - *old_head);
/* Set the actual entries for dequeue */ if (n > *entries) n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *entries;
typedefstruct { Elf32_Word st_name; /* Symbol name (string tbl index) */ Elf32_Addr st_value; /* Symbol value */ Elf32_Word st_size; /* Symbol size */ unsignedchar st_info; /* Symbol type and binding */ unsignedchar st_other; /* Symbol visibility */ Elf32_Section st_shndx; /* Section index */ } Elf32_Sym;
typedefstruct { Elf64_Word st_name; /* Symbol name (string tbl index) */ unsignedchar st_info; /* Symbol type and binding */ unsignedchar st_other; /* Symbol visibility */ Elf64_Section st_shndx; /* Section index */ Elf64_Addr st_value; /* Symbol value */ Elf64_Xword st_size; /* Symbol size */ } Elf64_Sym;
service.mercury:# set Mercury Parser API endpoint to `service.mercury:3000` on TTRSS plugin setting page image:wangqiru/mercury-parser-api:latest container_name:mercury networks: -public_access -service_only restart:always
service.opencc:# set OpenCC API endpoint to `service.opencc:3000` on TTRSS plugin setting page image:wangqiru/opencc-api-server:latest container_name:opencc environment: -NODE_ENV=production networks: -service_only restart:always
database.postgres: image:postgres:13-alpine container_name:postgres environment: -POSTGRES_PASSWORD=strong_password# 第三处修改,改成和第二处一样的密码 volumes: -~/postgres/data/:/var/lib/postgresql/data# persist postgres data to ~/postgres/data/ on the host networks: -database_only restart:always
networks: public_access:# Provide the access for ttrss UI service_only:# Provide the communication network between services only internal:true database_only:# Provide the communication between ttrss and database only internal:true
然后就可以运行了。
1
docker-compose up -d
之后想要修改docker-compose.yml时,先docker-compose down然后修改,改好后重新docker-compose up -d即可。注意以上命令都要在ttrss文件夹内执行。